

Эта статья содержит специальную терминологию. Но даже если вы не разбираетесь в предмете, вы найдёте выводы с результатами работы и узнаете, чем нейросеть полезна в продажах.
Рекомендации товаров по фото — не то же самое, что зарядка воды по телевизору или гадание по ВКонтакте. Это очень важная функция для торговых площадок. Представьте: вам понравилась некая вещь, вы захотели купить такую же и даже узнали магазин, но в нём тысячи товаров. И ещё интереснее, если вы хотите найти не такой же, а похожий товар.
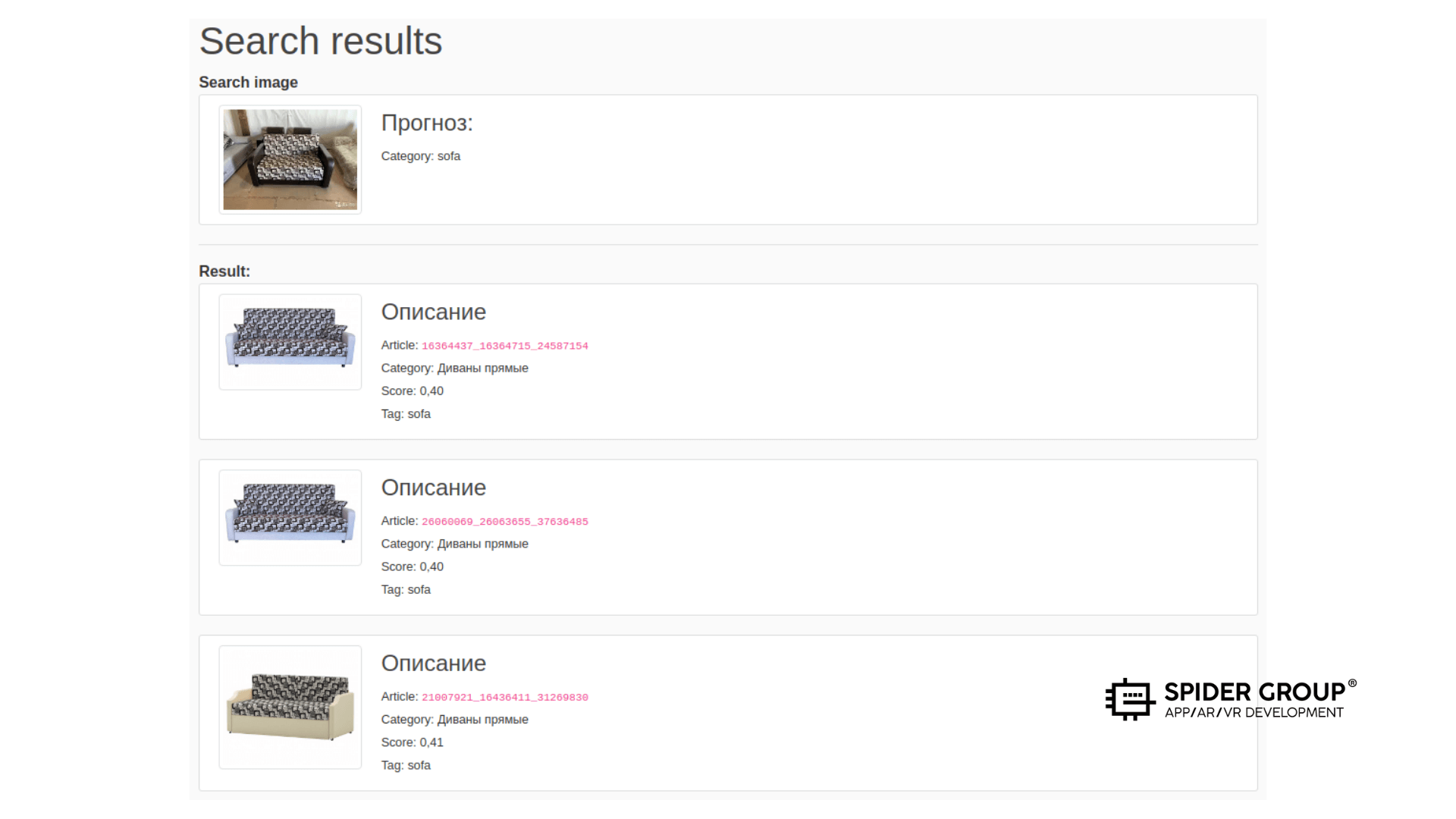
В каталоге не разобраться без инструкции, а найти хочется легко и прямо сейчас, как любому нормальному клиенту. Цель покупателя — купить, а не научиться пользоваться сайтом. В свою очередь, цель магазина — продать. Для достижения этих взаимно выгодных целей нужно убрать барьер между желанием и совершением покупки. Этим мы и занялись.
Задача
Мебельному интернет-магазину нужен инструмент для того, чтобы клиенты могли быстро найти конкретный товар или похожие на него товары в ассортименте, не прибегая к помощи консультантов. В процессе выяснилось, что решение полезно и для самих консультантов, которые теперь могут полагаться не только на 1С и память, но и на интеллектуальный поиск при помощи нашего алгоритма.
Если сформулировать задачу более точно, магазину нужен поиск похожего изображения. Два изображения можно считать похожими, если объекты, а точнее формы объектов на них, компоновка мелких деталей или цвет, одинаковы или содержат одинаковые более мелкие детали.
Подготовка данных
В нашем распоряжении находился набор из 170 000 изображений из базы данных магазина. База была разделена на конкретные товарные категории:
- Мягкая мебель
- Стулья
- Столы
- Шкафы
- Конструктивные элементы (навесы, ручки, и т.д.)
- Вешалки
- и много промежуточных вариантов
Первоначальный план заключался в использовании обученной свёрточной сети VGG19. Она может классифицировать изображение по тысяче возможных классов. Это позволяет получить матрицу признаков, по которым можно осуществлять подбор.
Структура слоёв VGG19:
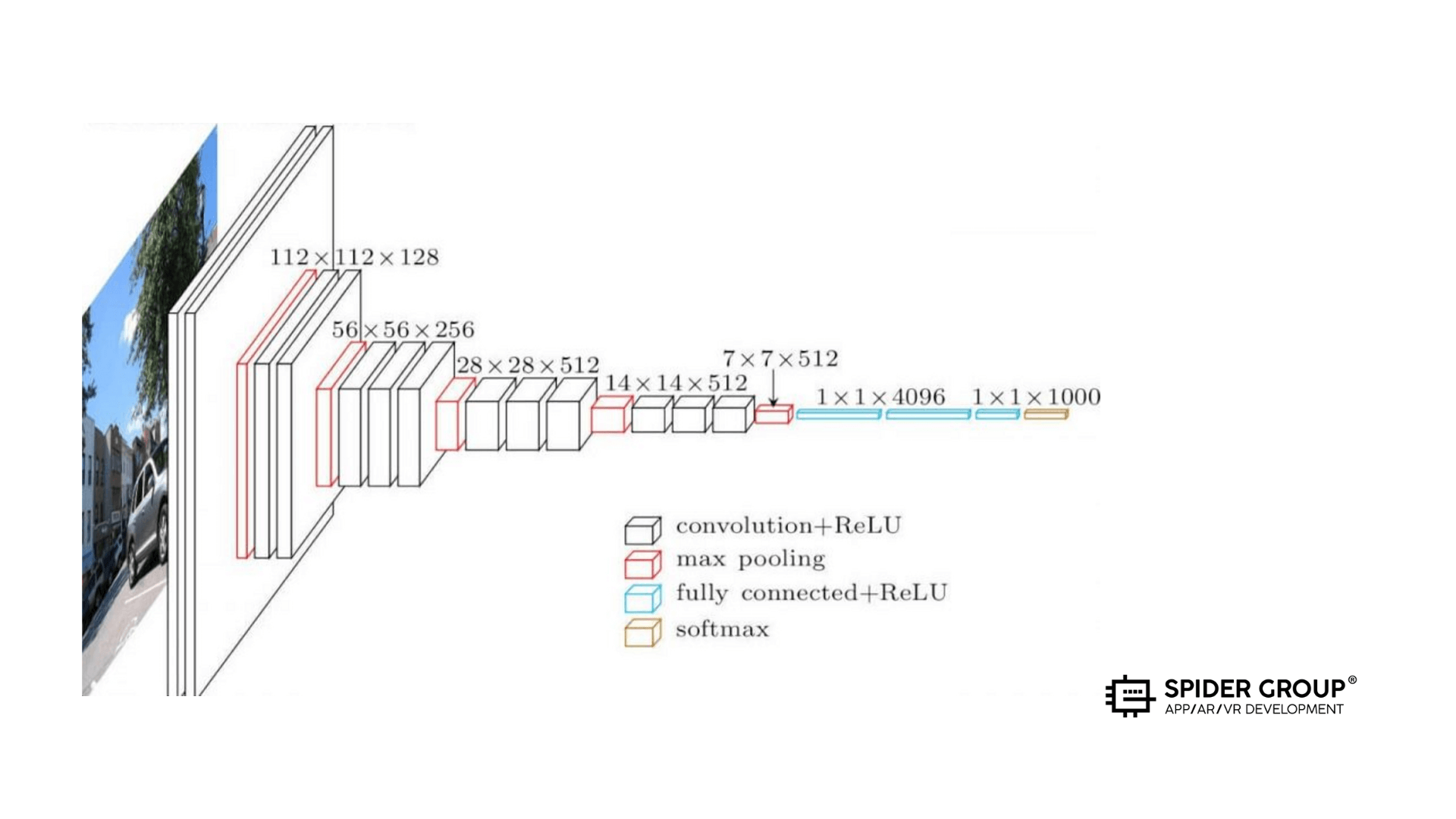
Зная тысячу признаков, нейросеть может отбирать изображения по соответствию с ними и на выходе выдавать массу результатов, которые можно отранжировать по уровню соответствия.
В реализации механизма классификации нам помог метод k-ближайших соседей (англ. k-nearest neighbors algorithm, k-NN) — метрический алгоритм для автоматической классификации объектов или регрессии.
В случае использования метода именно для классификации, алгоритм относит объект к тому классу, который является наиболее распространённым среди k-соседей данного элемента, классы которых уже известны. Иными словами, мы определяем, какие изображения наиболее близки искомому на основе выявленных признаков. Для этого мы воспользовались библиотекой NearestNeighbors из набора sklearn.
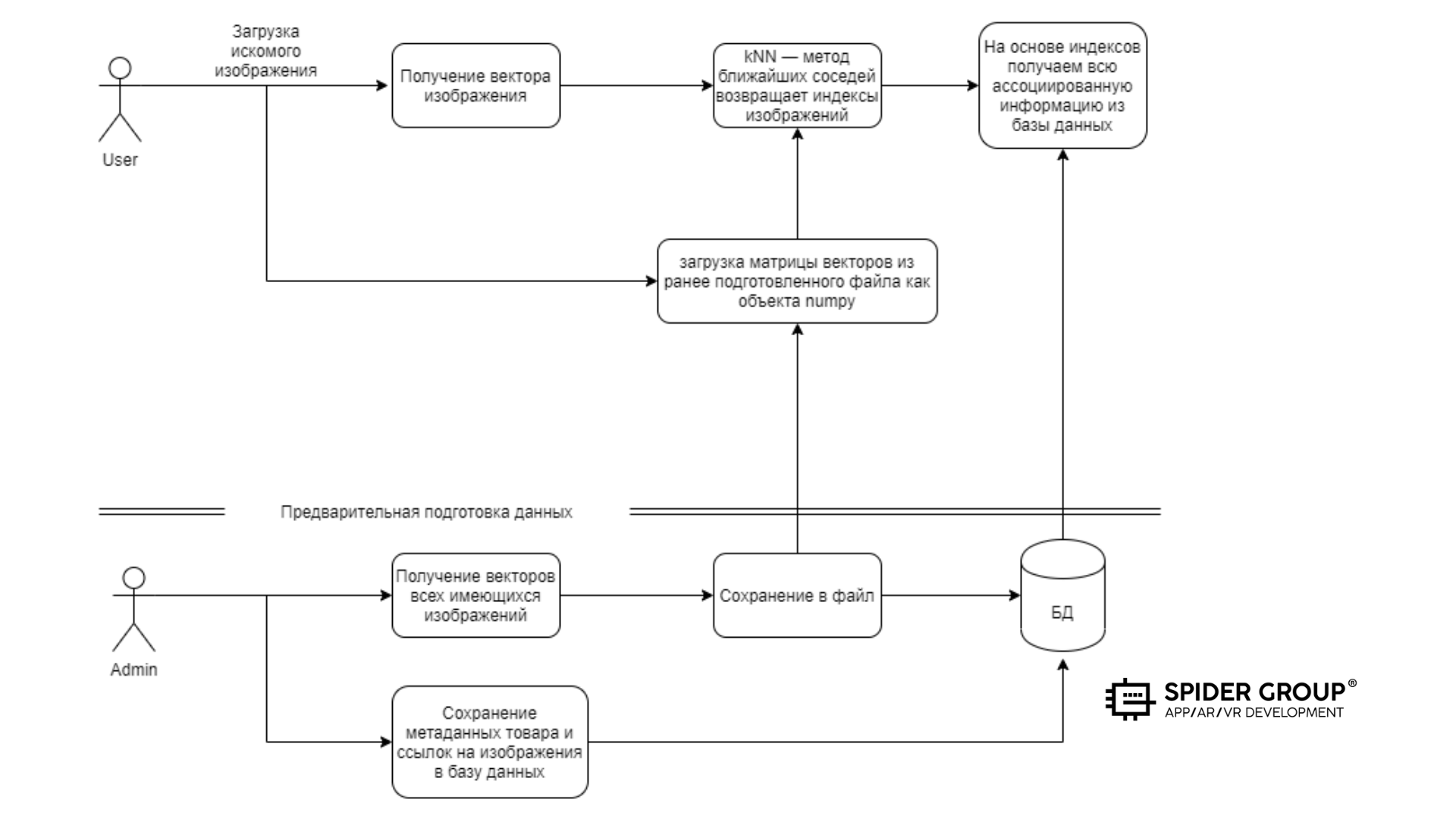
Процесс реализации можно представить в виде очень абстрактной блок-схемы:
Проблемы
Производительность. Расчёт k-NN на основе sklearn работает на основе предварительно подготовленной матрицы векторов, которую необходимо загрузить в память в виде numpy-объекта. Размер этой матрицы зависит от количества изображений. Чем больше каталог, тем большую матрицу необходимо держать в памяти.
При пробном деплое на сервере разработки столкнулись с проблемой: в зависимости от настроек, nginx выгружает воркеры из памяти после каждого запроса или после превышения определенного порога использования памяти. В результате пользователь мог ожидать отклика в течении 5–20 секунд, и чем больше изображений использовалось в каталоге, тем дольше происходило формирование ответа.
Качество. Подбор подобных изображений при наличии множества векторов из смешанных категорий происходит по вторичным признакам, таким как фон и малозначимые детали. Это даёт плохо предсказуемый результат и отражается на качестве финальной выборки.
Решения
В этой работе мы развиваем идеи, которые хорошо описал в своей статье Илья Сиганов. А далее постараемся передать опыт реального производственного внедрения технологии.
Проблему с производительностью удалось решить переносом кода с тяжёлым импортом данных, а точнее всего функционала предсказаний в отдельный микросервис, который взаимодействовал с кодом Django через систему очередей Redis. Это позволило значительно сократить время отклика.
Вторая проблема оказалась значительно сложнее. Признаки, выделяемые нейросетью на фотографии, не всегда имеют очевидную природу, отчего результат может быть неожиданным. Источниками ошибок послужили два момента:
- Матрица набора векторов, а следовательно, и набор используемых изображений, содержит не только только похожие основные объекты, но также похожие фоны, интерьеры или другие второстепенные детали.
- Выделяемые признаки не всегда имеют приоритетный характер.
Необходимо было закрыть оба источника.

Проблему с набором данных решили обработать в ручную и распределить по суперкатегориям, таким как мягкая мебель, стулья, шкафы и прочие. Далее мы удалили из каталога все изображения, не содержащие информации о самом товаре (схемы сборки, изображение фактур и тому подобное). Это обеспечило набор данных для подготовки векторов.
Идея состояла в создании некого коммутатора, который классифицирует объект и, в зависимости от определённой категории, осуществляет поиск ближайших соседей только в том хранилище векторов, который содержит целевой набор данных.
Для обучения классификатора мы использовали изображения объектов с разных сторон без предварительной разметки, но отбирали изображения таким образом, чтобы детектируемый объект не находился на фоне объектов из потенциально пересекающихся категорий. Точность детектирования при таком подходе не составляла более 90%, однако этого было достаточно, чтобы проверить на практике «коммутационный» подход.
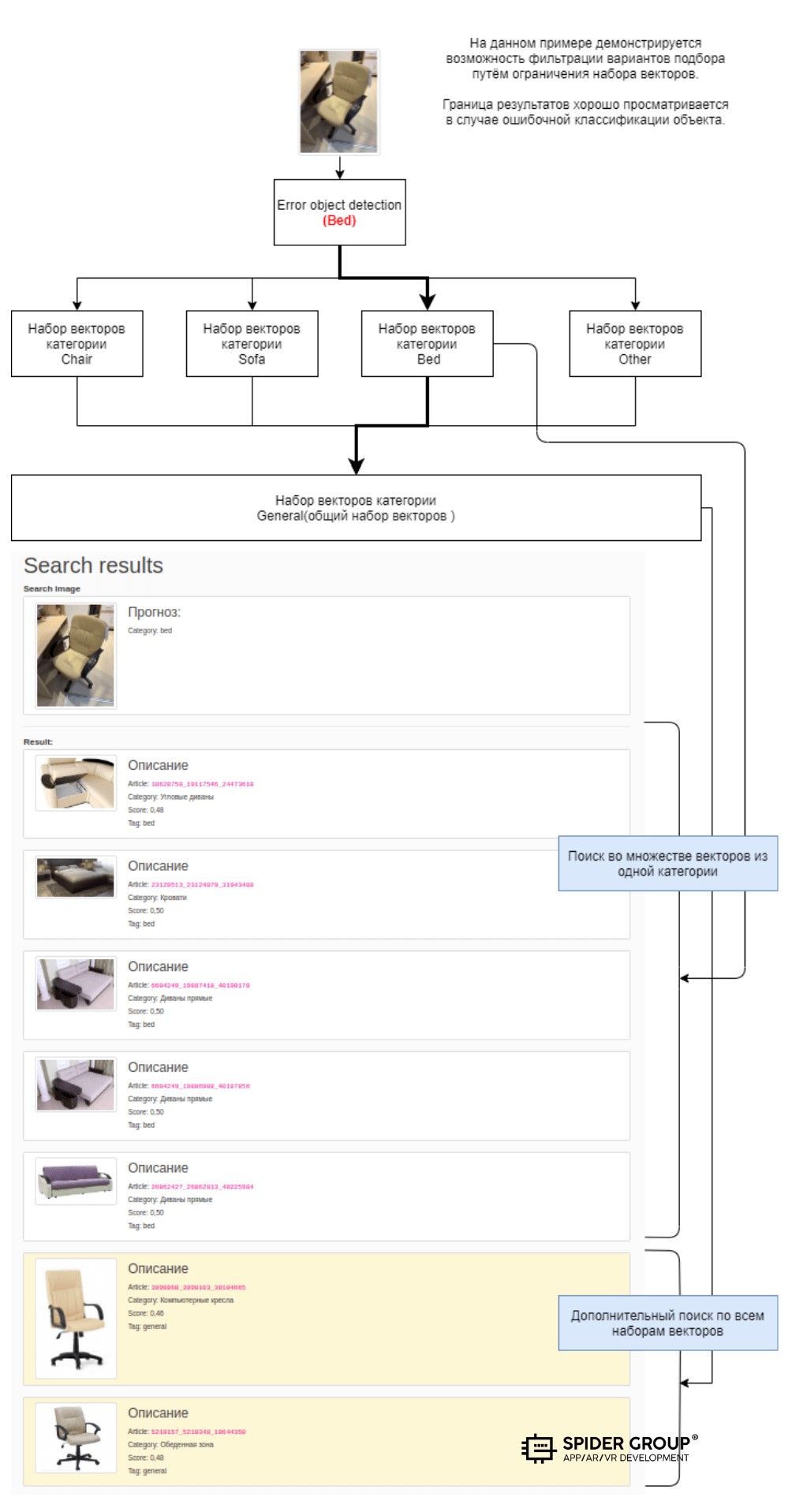
Практический результат эксперимента показал не совсем то, что мы ожидали:
-
-
- При точном определении категории результат поиска среди ярко выраженных индивидуальных признаков был неплохим. Например, изображение компьютерного кресла характерной формы с определённым типом рисунка позволяло найти действительно похожие объекты. Но если ставить целью поиск конкретной модели (зная что набор изображений данной модели присутствует в каталоге), то успех составлял примерно 30–80%, в зависимости от ракурса съёмки.
- Такие объекты как шкафы, комоды и подобные им, без ярко выраженных геометрических особенностей, при подборе «соседей» давали ещё больший разброс.
- Ошибочное определение категории приводило к еще более печальному варианту. Если кресло определилось как кровать, то найти среди множества кроватей нужное кресло вряд ли получится.
-
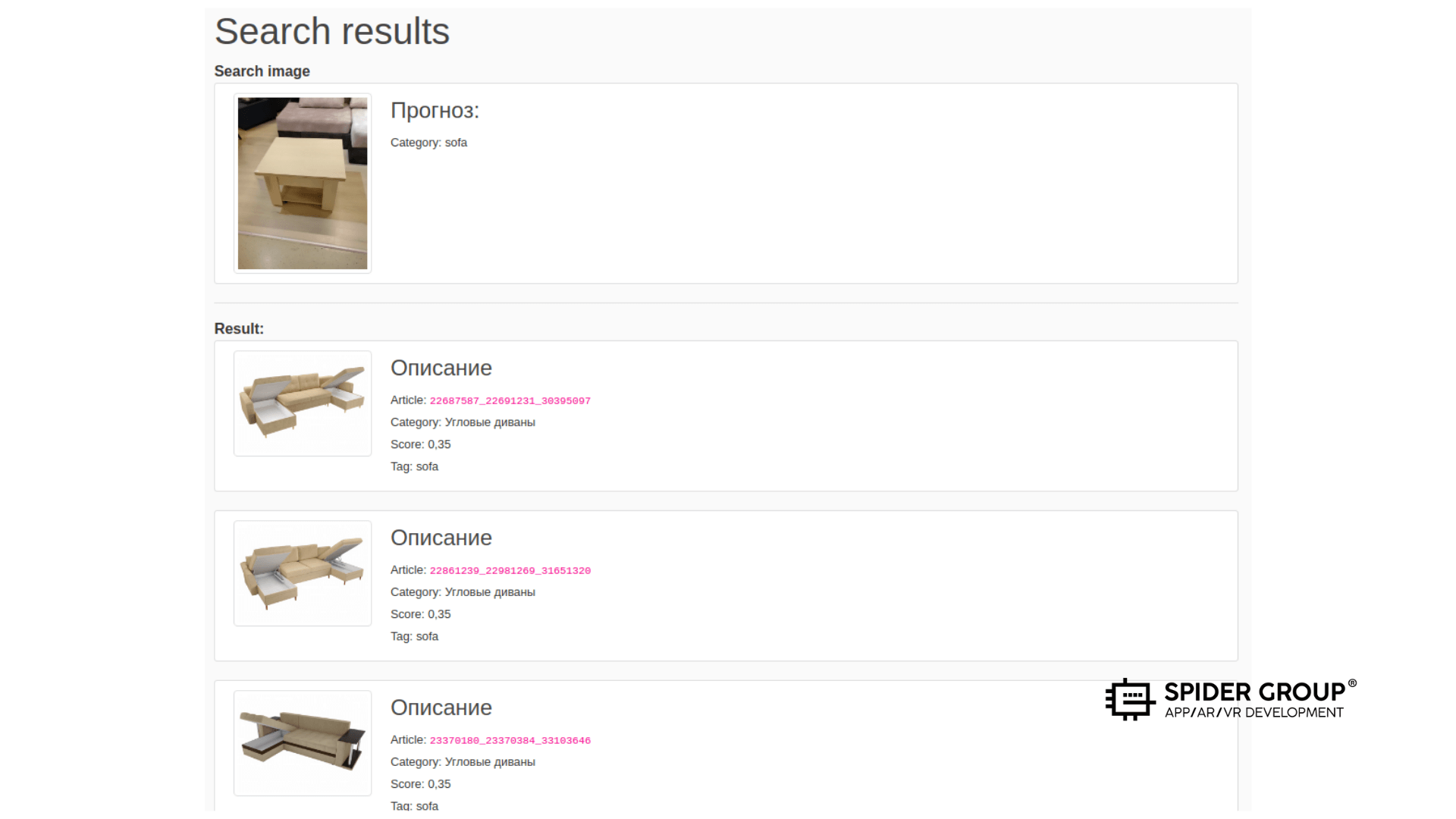
На следующем изображении видно, что произошло определение категории объекта с заднего фона. Следовательно, поиск шёл среди диванов. Странно то, что при этом нейросеть подобрала диван соответствующего типа — угловой. Возможно, комбинация предметов по соответствующим признакам воспринимается как угловой диван бежевого цвета.
Чтобы улучшить результат поиска, мы решили сделать три вещи.
Разделили классы на более мелкие категории, то есть категорию «мягкая мебель» на «мягкие кресла» и «диваны».
Добавили категорию «Другие» с целью обучить нейросеть распознавать неклассифицируемые объекты. Например, если существует две категории — стол и стул, а фотография на входе нейронной сети содержит изображение стиральной машины, то ожидаемый результат — «Другие», а не тот случай когда нейросеть возвращает вероятность 30%, что на фото изображён стол, а не стул.
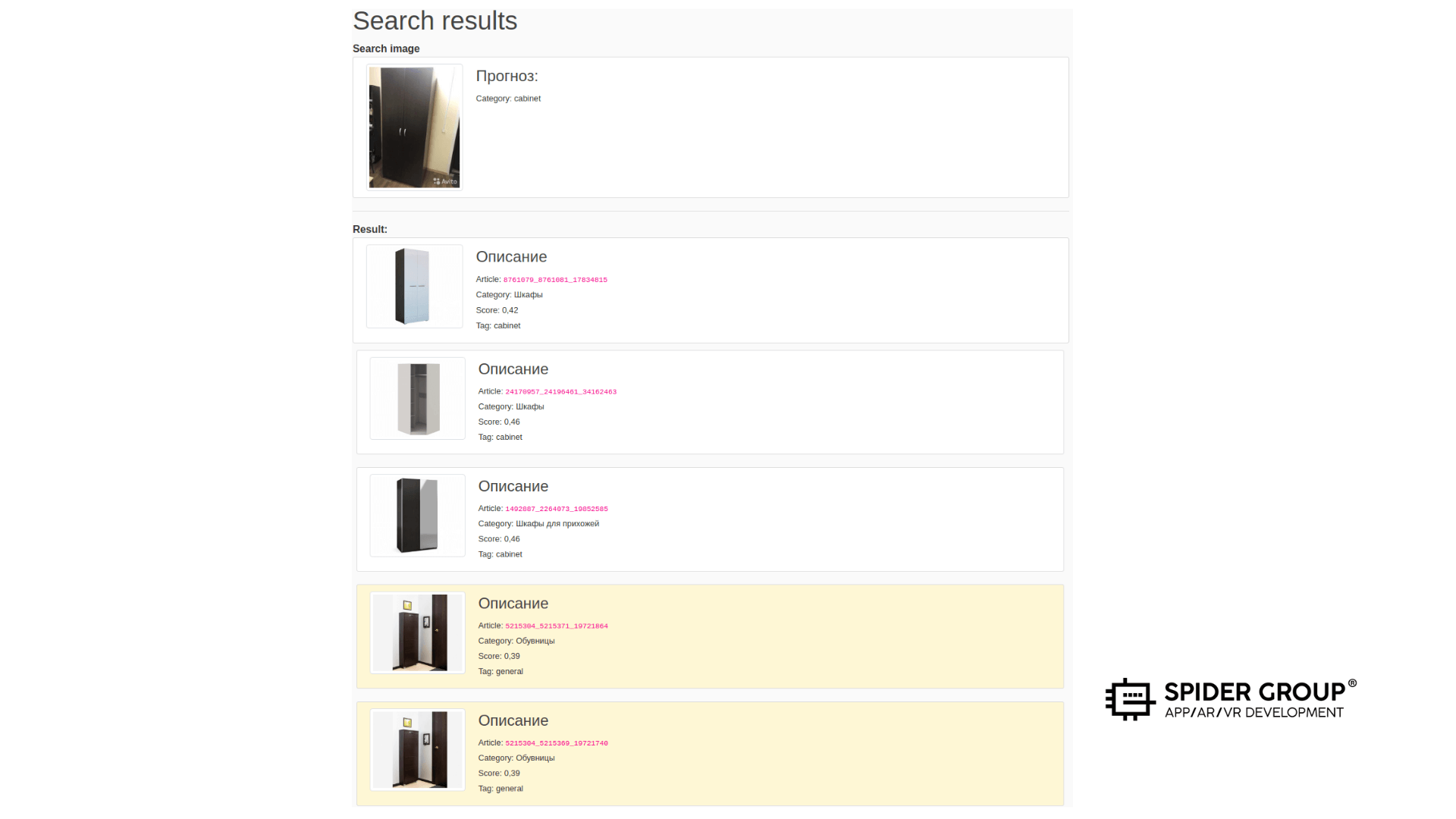
Создали общий набор векторов, в который вошли все категории изображений. Это запасной вариант на случай, если нейронная сеть ошибётся с определением категории или вектор искомого объекта окажется в другой категории из-за человеческого фактора. В таком случае сеть проведёт дополнительный поиск по общей матрице векторов. Как показано на примере, дополнительный поиск в общей категории позволил найти шкаф похожего дизайна в категории «Обувницы», хотя данная категория не находится в составе суперкатегории «cabinet».
Чего мы добились
Мы сумели применить машинное обучение для более удобного интерфейса подбора товарных наименований. Теперь наша система умеет:
- подбирать товары такой же категории по фотографии;
- делать предложения из других категорий, основываясь на дизайне (по цвету и форме). Например, если вы скармливаете нейросети фото кресла, она попробует предложить вам подходящие подушки, диван, накидки;
- контролировать дубликаты при заполнении товарного каталога;
- искать варианты, схожие по форме и цвету, в разных каталогах. Например, такой же стул, но из другой серии и не пересекающийся по характеристикам. Для некоторых магазинов это огромная часть ассортимента.
Что будет дальше
Разработка проекта продолжается. И даже после релиза его можно будет улучшать — такова особенность любого сложного технологичного решения. Чтобы выдать максимальный результат, мы выявили главные проблемы, над которыми предстоит поработать.
Основной целью проекта является создание более простого инструмента взаимодействия пользователя с каталогом товаров. Здесь предстоит решить проблему гарантированного поиска конкретной модели изделия по фотографии в неподготовленном каталоге. Процент ошибочного подбора остается достаточно большим. Дальнейшие изыскания в данном направлении, вероятно, дадут более эффективный способ реализации.
Мы находимся в поисках способа регулировать подбор в зависимости от наличия товара на складе или его доступности для заказа в конкретном городе. Коллекция векторов представляет собой статическую матрицу, перестроение которой невозможно выполнить в момент запроса пользователя. Была надежда, что проект NearPy позволит решить данную проблему, но качество подбора ближайших соседей оказалось неприемлемым.
Тем не менее, удалось неплохо осуществлять поиск в наборе изображений со схожими признаками. Это позволяет использовать данную реализацию для вспомогательного функционала, например, чтобы при добавлении нового изображения убедиться, что ранее оно не добавлялось.
Использование VGG19 и VGG16 не позволяет достичь самых амбициозных из поставленных целей. Но мы рассчитываем, что эксперименты с другими свёрточными сетями покажут более качественный результат.
***
Мы обязательно поделимся дальнейшими результатами этой работы. Если вам понравилась статья, не забудьте поделиться ей с друзьями. Чтобы не пропустить наши статьи и новости компании, подписывайтесь на Spider Group в Facebook, ВКонтакте, Twitter и Instagram.
В Spider Group на вас работает более чем двадцатилетний опыт в разработке мобильных приложений, веб-разработке сайтов, серверных проектов, дополненной реальности, искусственного интеллекта и Интернета вещей.



{kind=link}