

FASTEP, наш внутренний стартап, предлагает предприятиям оптимизировать труд с помощью интерактивных инструкций и видеосвязи с дополненной реальностью. Это работает в мобильных приложениях — в том числе, на iOS.
Важной частью FASTEP является модуль классификации и идентификации техники на основе компьютерного зрения. Для пользователя всё выглядит очень просто. Покажите фронтальную панель техники в камеру, а софт предложит совпадение из базы данных и инструкции именно для того, что перед вами. С таким инструментом не нужно вводить идентификационный номер модели или искать её по внешнему виду.
Чтобы это было так быстро и удобно, пришлось глубоко оптимизировать процесс.
Обычная схема — когда приложение загружает кадры с камеры на сервер, нейросеть на сервере производит вычисления и отдаёт обратно решение. Здесь есть проблемы:
- Пользователи любят тестировать приложения на чём угодно и шлют на сервер фотографии всего, но только не нужных нам вещей. Бэкенд нагружается бесполезной работой
- Появляются задержки от сервера
- Решение становится излишне зависимым от качества интернет-соединения
Мы поняли, что нужны варианты оптимизации. Первым стала переработка архитектуры решения. Вторым — конвертация сетей на библиотеке PyTorch в нативный Core ML, потому что нативное должно быть быстрее и экономичнее стороннего.
Часть вычислений — на смартфон
Мы разделили процесс определения модели на две части: классификацию объекта и определение конкретной модели техники. Затем перенесли определение класса техники на смартфон. Таким образом «первичный» анализ видеопотока взяло на себя пользовательское устройство.
Нейронная сеть на смартфоне определяет класс техники (например, «Посудомоечная машина»). Если изображение классифицировано, оно уходит на сервер. Мы также можем узнавать, что объект не принадлежит ни к одному из классов. Так заранее отсекаются неправильные варианты, снижается нагрузка на серверную часть. Теперь на сервер приходят уже классифицированные данные.
Архитектура бэка
До этого определением конкретной модели техники занималась одна нейросетка. После ряда экспериментов мы поняли, что более качественный результат дают сети, которые натренированы определять модель в пределах одного класса: одна занимается стиральными машинами, другая — микроволновками и так далее. Мы создали такие сети и научили бэкенд маршрутизировать запросы на основании данных о классе с устройства пользователя.
Ещё одна проблема оказалась неожиданно важной. Производители техники выпускают её сериями, в которых модели отличаются лишь некоторыми параметрами и внешне абсолютно или почти одинаковы. Печально, но мы собирали данные для обучения без учёта этого факта. В таких сериях сеть правильно находила одну модель, а затем принимала другую за неё же, а мы помечали это неправильным ответом. Звучит как наказание за правильные ответы — несправедливо!
Эту проблему нельзя решить без пересмотра дизайна бытовой техники, зато можно обойти. Мы изменили подход к сбору данных и теперь группируем однотипные модели. Благо, инструкции к этим моделям тоже почти одинаковые.
Зачем конвертировать PyTorch в Core ML
Классификацию на мобильном устройстве мы запустили. Но вычисления производились на CPU и GPU, без нейропроцессора — и это не очень хорошо. Злую шутку играет универсальность PyTorch: его понимают любые устройства, но такие сети не могут похвастаться глубокой оптимизацией под конкретное железо.
Устройства греются, батарея скоропостижно разряжается, скорость обработки видеопотока держится на уровне шести кадров в секунду. О бесшовности с такой скоростью речь идти не может.
Логичным выходом стала конвертация нейронной сети в Core ML.
Core ML оптимизирует производительность нейросетевых вычислений на устройствах Apple, распределяя задачи между центральным процессором, графическим процессором и нейропроцессором для минимизации расходов памяти и энергии. Запуск модели строго на устройстве пользователя устраняет необходимость в сетевом трафике на данном этапе.
Результаты превысили наши ожидания. Благодаря распараллеливанию задач, Core ML оказался быстрее в 2–2,5 раза.

От создания PyTorch-модели к Core ML
Итак, на входе есть модель в PyTorch, а на выходе нужно получить модель Core ML для встраивания в приложение.
Для конвертации нейронных сетей мы использовали библиотеку coremltools. Для задания дополнительных параметров и проверки преобразованной модели также применялись библиотеки PyTorch, NumPy и PIL.
Этапы:
- Создание и инициализация PyTorch-модели
- Изменение PyTorch-модели для интерпретации результатов
- Преобразование модели PyTorch в TorchScript
- Конвертирование модели TorchScript в MLModel
- Квантирование
- Проверка модели
Создание и инициализация PyTorch-модели
Для корректного преобразования сеть должна быть создана без квантирования и без оптимизации с помощью метода optimize_for_mobile.
resnet50 = models.resnet50(pretrained=False)
fc_in_features = resnet50.fc.in_features
resnet50.fc = nn.Linear(
in_features=fc_in_features,
out_features=7)
resnet50.load_state_dict(torch.load("./Models/resnet50.pt", map_location=torch.device('cpu')))
Преобразования выхода PyTorch-модели для интерпретации результатов
Выход модели можно преобразовывать либо на уровне PyTorch, либо на уровне приложения с помощью Accelerate. PyTorch позволяет сделать это быстрее. Добавление сигмоиды в модель выглядит так:
torch_model = torch.nn.Sequential( resnet50, nn.Sigmoid())
Преобразование модели PyTorch в TorchScript
Перед преобразованием нужно обязательно перевести модель в режим вычислений:
torch_model.eval()
Преобразовать в TorchScript можно с помощью методов trace и script. Trace фиксирует модели в соответствии с тестовым входным тензором, что позволяет сделать модель быстрее, но при этом, если модель имеет внутри условные операторы или циклы с переменным диапазоном, сконвертированная модель может работать неправильно. Чтобы избежать проблем, trace нужно использовать со script.
Для преобразования с помощью trace необходимо использовать случайный тензор заданной размерности (либо какой-то определённый, например, полученный из тестового изображения):
input_shape = (3, 224, 224) example_input = torch.rand(1, *input_shape) traced_model = torch.jit.trace(torch_model, example_input)
Метод script, помимо модели, не требует дополнительных аргументов.
scripted_model = torch.jit.script(torch_model)
Преобразование модели TorchScript в MLModel
Метод convert из coremltools имеет следующие параметры:
- model — модель PyTorch, преобразованная в TorchScript-объект
- source: str — название фреймворка, которое можно вывести автоматически, исходя из параметра model
Inputs — массив входных аргументов TensorType либо ImageType. Можно использовать оба этих типа. Но если в качестве входа нейронной сети ожидается изображение и не требуется его особая предобработка, нужно использовать ImageType, так как это ускоряет преобразование. Можно также самостоятельно преобразовать изображение в тензор и передать его в сеть. У ImageType есть аргументы, которые позволяют делать предобработку изображения с учётом значений среднего и стандартного отклонения, использовавшихся при обучении сети:
input = ct.ImageType( color_layout='RGB', scale=1.0/255.0/0.226, bias=(-0.485/0.229, -0.456/0.224, -0.406/0.225), shape=example_input.shape)
Classifier_config — с помощью этого параметра можно именовать выходные классы нейронной сети. Этот параметр можно не указывать, но его использование даёт пару преимуществ:
- Core ML воспринимает модель как классификатор и автоматически сортирует выход от наибольшего значения к наименьшему;
- в XCode создаётся вкладка «Preview», на которой можно проверить сеть на тестовых изображениях.
Полный вызов метода конвертации и сохранения:
cml_model = ct.convert(
traced_model,
inputs=[input],
classifier_config=ct.ClassifierConfig(class_labels)
cml_model.save('Models/Resnet50.mlmodel')
Квантирование
Позволяет уменьшить размер модели с помощью уменьшения весов с 32 бит до меньшего значения — например, 8 — которое можно указать в аргументах. Можно также указать один из трёх алгоритмов (linear, linear_symmetric, kmeans_lut).
В coremltools есть специальный метод для квантирования:
model_8bit = quantization_utils.quantize_weights(
cml_model,
nbits=8,
quantization_mode="linear")
model_8bit.save('Models/Resnet50_8bit.mlmodel')
Проверка модели
Проверить качество конвертирования можно непосредственно в Python. Для этого необходимо загрузить модель из файла и вызвать метод predict, который принимает на вход словарь с ключами из массива inputs и значением типа ndarray, если предполагается тензор, или PIL.Image, если изображение.
model = ct.models.MLModel('Models/Resnet50.mlmodel')
prediction = model.predict({'input.1': img})
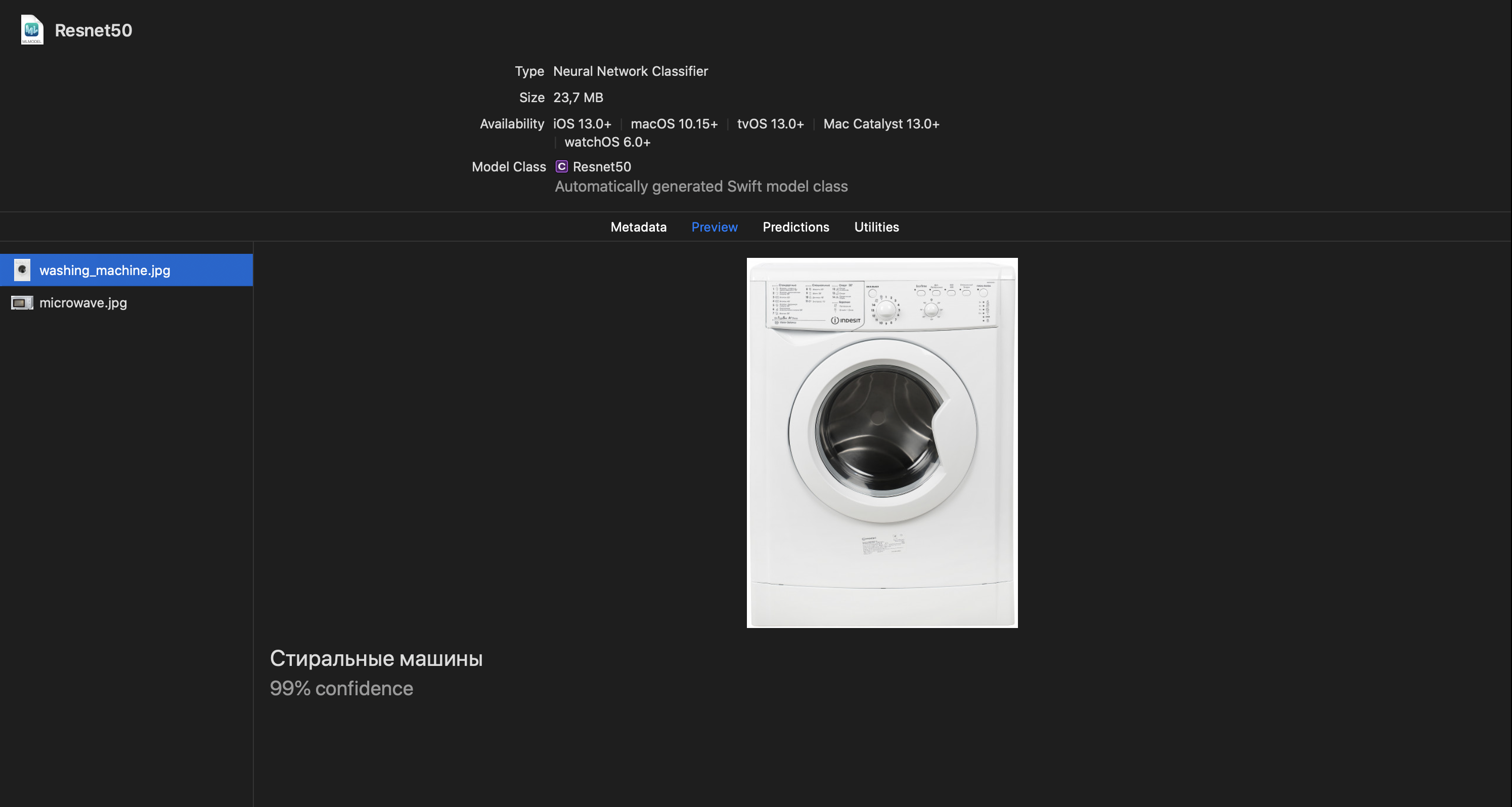
А получилось вот что
Конвертация в Core ML повысила скорость обработки до более чем 30 кадров в секунду. Это означает решение задачи практически в реальном — для человека — времени. Бонусом стало снижение рабочей температуры смартфона и экономия заряда. Всё это очень важные части восприятия приложения пользователем. И теперь мы можем применять такое решение не только в собственной платформе, но и для заказчиков Spider Group. Заказывайте отечественные нейросетевые классификаторы!
P. S.
А как же Android? Теперь мы сосредоточимся на оптимизации под Neural Networks API. Это будет гораздо веселее, потому что там есть прекрасное многообразие устройств и версий операционной системы.
В Spider Group на вас работает более чем двадцатилетний опыт в разработке мобильных приложений, веб-разработке сайтов, серверных проектов, дополненной реальности, искусственного интеллекта и Интернета вещей.



{kind=link}